In the field of deep learning, convolutional neural networks (CNNs) are fundamental for tasks like image recognition, object detection, and more. Among various architectures, VGG and LeNet-5 stand out due to their simplicity, effectiveness, and influence on modern neural networks. While LeNet-5 laid the groundwork for CNNs in the 1990s, VGG, introduced later, demonstrated the impact of depth on model performance.
LeNet-5 Architecture
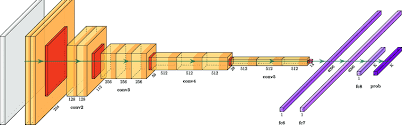
LeNet-5, developed by Yann LeCun and his collaborators in 1998, was one of the first successful CNNs. It was designed primarily for handwritten digit recognition, such as for the MNIST dataset. lenet 5 architecture
Architecture Overview
LeNet-5 consists of seven layers (not including input) with a mix of convolutional, subsampling (pooling), and fully connected layers.
- Input Layer:
- Input size: 32×3232 \times 32 grayscale images.
- MNIST digits (28×2828 \times 28) are padded to 32×3232 \times 32 for this architecture.
- Layer 1 – Convolution:
- Filter size: 5×55 \times 5.
- Number of filters: 6.
- Stride: 1.
- Output size: 28×28×628 \times 28 \times 6.
- Layer 2 – Subsampling (Pooling):
- Type: Average pooling.
- Filter size: 2×22 \times 2.
- Stride: 2.
- Output size: 14×14×614 \times 14 \times 6.
- Layer 3 – Convolution:
- Filter size: 5×55 \times 5.
- Number of filters: 16.
- Output size: 10×10×1610 \times 10 \times 16.
- Layer 4 – Subsampling (Pooling):
- Type: Average pooling.
- Filter size: 2×22 \times 2.
- Stride: 2.
- Output size: 5×5×165 \times 5 \times 16.
- Layer 5 – Fully Connected:
- Number of neurons: 120.
- Layer 6 – Fully Connected:
- Number of neurons: 84.
- Layer 7 – Output:
- Number of neurons: 10 (corresponding to the 10 digit classes).
Key Features:
- Activation Function: Tanh.
- Weight Sharing: Reduces parameters.
- Optimized for digit recognition tasks.
VGG Architecture
VGG (Visual Geometry Group), introduced in 2014 by Simonyan and Zisserman, is known for its simplicity and depth. VGG-16 and VGG-19, with 16 and 19 weight layers respectively, are the most commonly used versions.
Key Idea
The VGG network emphasizes the use of small convolutional filters (3×33 \times 3) throughout the network, showing that depth significantly improves model performance.
Architecture Overview
VGG-16 consists of 16 weight layers: 13 convolutional layers and 3 fully connected layers.
- Input Layer:
- Input size: 224×224×3224 \times 224 \times 3 RGB images.
- Convolutional Layers:
- Small 3×33 \times 3 filters.
- Depth doubles after every few layers (64, 128, 256, 512).
- Pooling Layers:
- Max pooling with 2×22 \times 2 filters and stride 2.
- Applied after blocks of convolutional layers.
- Fully Connected Layers:
- Three fully connected layers with 4096, 4096, and 1000 neurons, respectively.
- Output Layer:
- Softmax layer for classification (1000 classes in ImageNet).
Detailed Configuration (VGG-16):
- Block 1:
- Two 3×33 \times 3 convolutions (64 filters), followed by max pooling.
- Block 2:
- Two 3×33 \times 3 convolutions (128 filters), followed by max pooling.
- Block 3:
- Three 3×33 \times 3 convolutions (256 filters), followed by max pooling.
- Block 4:
- Three 3×33 \times 3 convolutions (512 filters), followed by max pooling.
- Block 5:
- Three 3×33 \times 3 convolutions (512 filters), followed by max pooling.
- Fully Connected Layers:
- Flatten the output and connect to dense layers.
Key Features:
- Consistent filter size (3×33 \times 3).
- Increased depth for feature hierarchy.
- Large number of parameters (138M for VGG-16).
- Designed for ImageNet classification.
Comparison of LeNet-5 and VGG
| Feature | LeNet-5 | VGG |
|---|---|---|
| Year Introduced | 1998 | 2014 |
| Input Size | 32×3232 \times 32 (grayscale) | 224×224224 \times 224 (RGB) |
| Depth | 7 layers | 16–19 layers |
| Filter Size | 5×55 \times 5 | 3×33 \times 3 |
| Pooling Type | Average pooling | Max pooling |
| Applications | Digit recognition | Image classification |
| Parameters | ~60K | 138M (VGG-16) |
Conclusion
Both LeNet-5 and VGG architectures have significantly influenced the evolution of CNNs. LeNet-5 demonstrated the feasibility of deep learning for digit recognition, while VGG emphasized the importance of depth and small filters, setting a foundation for more complex architectures like ResNet and Inception. Their simplicity and effectiveness make them ideal for understanding the core principles of CNNs.



